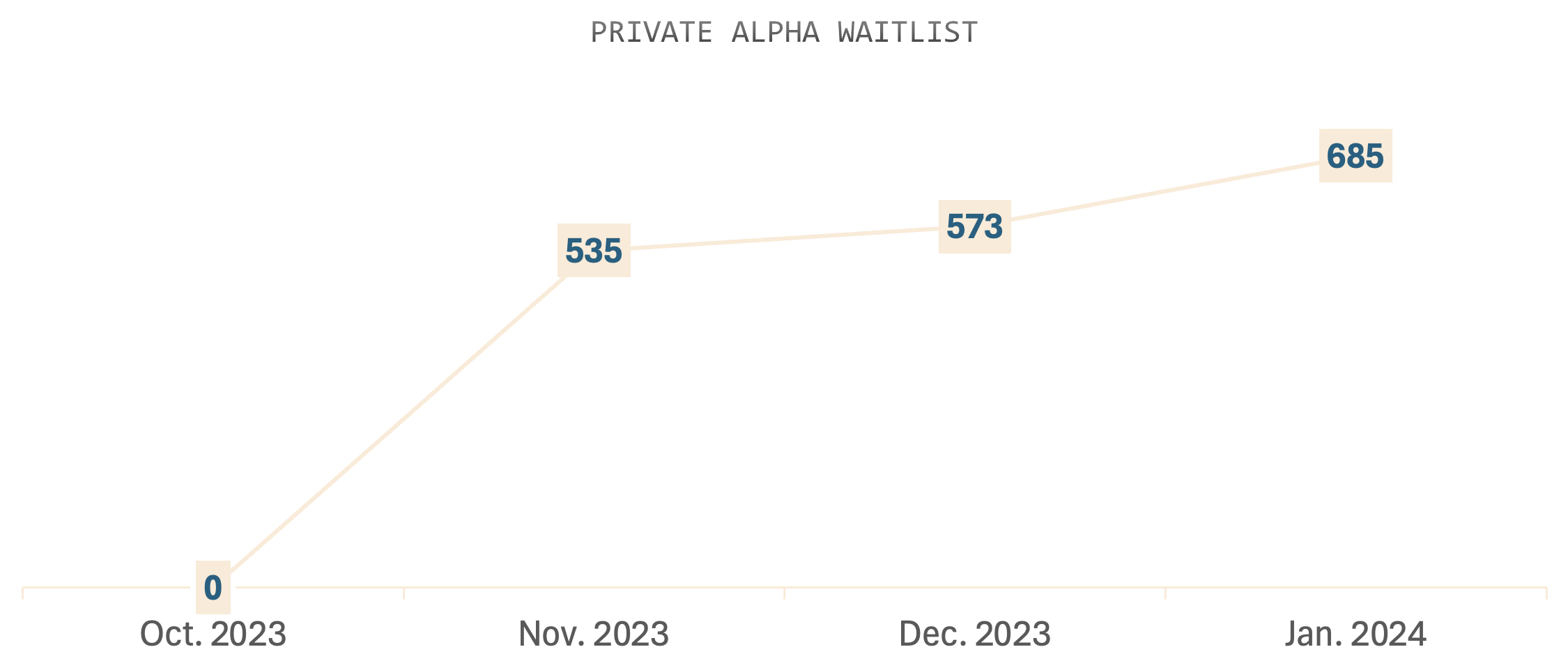
The Pitch
The complexity of software has exploded over the last decades, and the trend is accelerating. Applications consist of more and more internal and external services that need to interact with each other. And in complex systems, failure is unavoidable. The best we can do is to build applications with failure in mind.
Flawless is as tool that excels when it comes to interacting with unreliable services.
It allows developers to write code as if nothing could go wrong, simplifying the
development process, reducing error handling boilerplate and saving time. At the
same time, it provides automatic recovery and insight if things do go wrong.
In case an external service fails, flawless will retry the call. In case it's unavailable, flawless will wait until it's back up. And in case that flawless fails itself, it can reliably continue from exactly where it stopped after a restart, without any data loss.
The Use Cases
Flawless is a versatile tool and can be applied to different domains, but there are 3 scenarios where it shines the most:
1. Long-running jobs
If you have a workflow that takes days or months to finish, the likelihood of failure increases. And the longer the job takes before failure, the more painful it is to restart or debug.
The architecture of flawless allows any workflow to seamlessly continue from where it stopped, without the needs to start all the way from the beginning. No matter if the failure is caused by your own code or an external system, flawless can help in both cases.
2. Observability
For flawless to be able to reconstruct and continue the execution, it contains a log of all side effects that were executed. This makes it a perfect observability tool. Every workflow can be analyzed, no matter if it's still running or already finished execution.
3. Automatic recovery
In many cases, flawless can automatically recover from issues and drive the execution until completion. It can also help prevent failure propagating through the system. If one service fails, flawless will pause the execution of workflows depending on it, and wait for it to come back online.
The Team

Founder & CEO; Flawless is based on all the learnings I made over the last 3 years, while building tools for distributed fault-tolerant systems at lunatic. Prior to lunatic, I worked at CERN where I developed observability tools for a cluster of 1,000+ machines.